Dans les coulisses des services IA d’un éditeur de logiciels par Laurent M.
L'IA bouleverse l'industrie des éditeurs de logiciels. En quelques années, nous sommes passés de sentiments mitigés - impressionnés, sceptiques, enthousiastes, craintifs - à une démarche résolue, rationnelle, de transformation progressive de nos outils, tant sur les méthodes d'élaboration (codage, tests automatisés) que sur les nouvelles fonctionnalités que l'IA rend possible.
Les éditeurs quittent progressivement le champ exploratoire des débuts - une première démo, un POC pour sentir l'appétit des clients - à une approche plus intégrée et industrielle, dans la continuité des travaux classiques d'un éditeur, mais avec des spécificités propres à l'IA.
Nous en partageons ici quelques-unes, autour d’un exemple : la solution d'aide à l'analyse des offres que nous avons développée et lancée le mois dernier pour nos clients acheteurs publics.
Comme pour un processus métier classique ou une chaîne industrielle, la décomposition en étapes unitaires est primordiale, puisqu'elle permet, dans une logique de taylorisation, d'identifier le plus finement possible les zones de performance et de sous performance. Une partie de ces étapes connaît un traitement logiciel classique (algorithmes, calculs, etc.), mais de nouvelles procédures spécifiques sont mises en place pour les tâches concernées par l'IA.
1 - Choix du type de composant technique par type d'action à réaliser
- OCR, fonction usuelle de reconnaissance de caractère, où l'IA permet d'ajuster un mot mal reconnu grâce au sens général du texte concerné. C’est un point de passage indispensable entre les sources documentaires historiques (PDF, archives, images) et les chaînes de traitement par l’IA, en convertissant ces supports en texte et en tokens directement exploitables par les modèles IA.
- Base de données vectorielle : composant clé des architectures de Retrieval-Augmented Generation (RAG), c’est l'outil qui transforme les extraits documentaires en "vecteurs", les stocke, et qui permet de les retrouver plus tard en fonction de critères de proximité ("colinéarité") ; une recherche ne se fait plus par mots clé, mais par le sens des paragraphes analysés.
- Modèles de langage (LLM), eux-mêmes décomposés en
- Petits modèles de langage : adaptés aux tâches simples et bien définies (sélection, extraction, classification, notation), les petits LLM privilégient la rapidité d’exécution, la maîtrise des coûts et une empreinte environnementale réduite. Par exemple, “mistral-small” suffit pour suggérer une note sur un critère à partir d'un commentaire détaillé et d'un barème précis.
- Modèles de langage intermédiaires : destinés aux tâches plus avancées nécessitant une compréhension fine et un traitement élaboré des contenus (reformulation, synthèse, génération argumentée), avec un compromis assumé entre performance, coût et consommation de ressources. Par exemple, on privilégie “mistral-medium” pour produire le commentaire argumenté d'une offre sur un critère de notation.
- Modèles de raisonnement (reasoning) : conçus pour les tâches de réflexion et d’analyse complexe, impliquant enchaînement logique, prise de décision ou arbitrage à partir de règles, de contraintes ou de contextes multiples. Par exemple, les modèles “magistral” sont les modèles de raisonnement de Mistral, utilisés pour générer une grille de notation.
- Modèles fine-tunés : modèles de langage spécialisés, entraînés spécifiquement sur un usage ou un périmètre fonctionnel donné. Cet entraînement ciblé permet à un modèle de taille réduite d’atteindre, sur une tâche précise, des performances comparables à celles d’un modèle beaucoup plus volumineux, tout en restant plus rapide et plus économique. Par exemple, le modèle open source “mistral-small” entraîné sur des milliers d’exemples devient excellent dans l’extraction de champs précis de documents de marchés (CCAP et RC principalement) ou la production de résumé (de CCTP notamment).
2 - Définition de différents niveaux d'assistance de l'IA à proposer à l'utilisateur
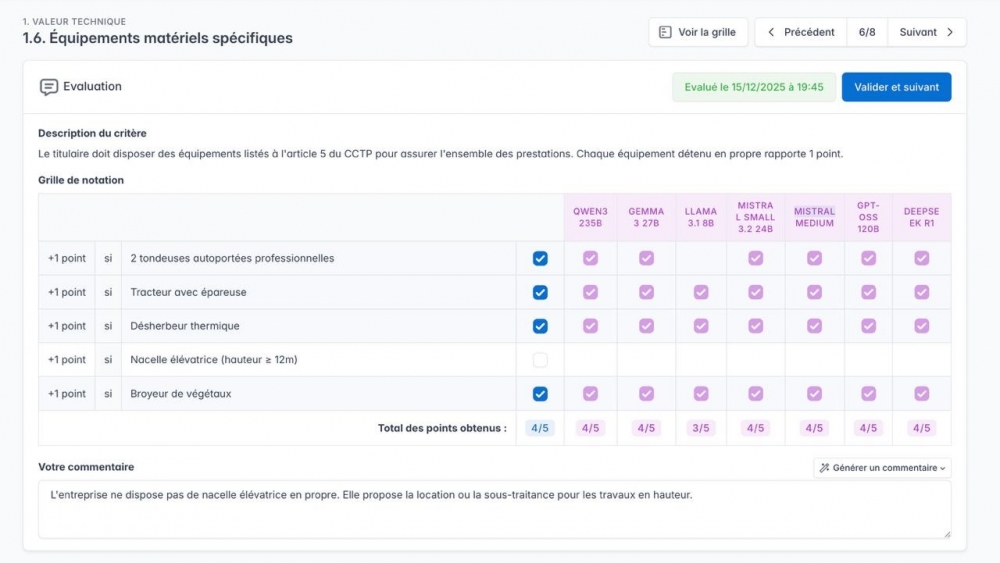
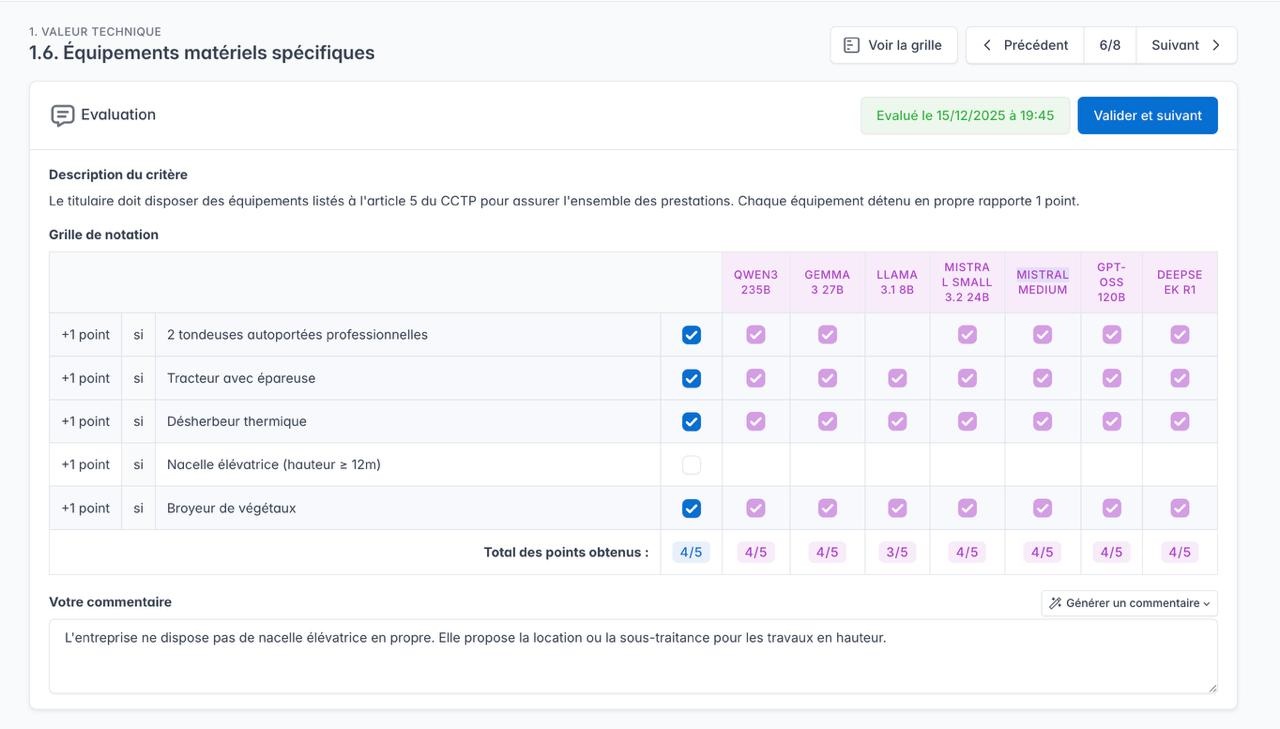
Selon la sensibilité du sujet ou des données traitées, le caractère très pointu d'un traitement, un utilisateur peut être sceptique ou réticent à utiliser un outil IA. Pour autant, au sein d'un travail critique à réaliser, certaines sous-parties le sont moins et peuvent bénéficier d'une aide IA, de façon moins sensible. Par exemple, lors d'une analyse des offres reçues dans un marché public, la partie la plus critique est l'analyse du mémoire technique des candidats (informations très confidentielles) et la notation (qui a un effet direct sur l'attribution du contrat). En revanche, la construction d'une grille d'analyse, et la production d'un barème pour chaque critère sont des étapes de sensibilité inférieure. Un acheteur public est ainsi rassuré par la possibilité d'utiliser son outil IA avec progressivité, en ne l'activant que pour la première étape de création d'une grille de notation.
3 - Observabilité des modèles IA
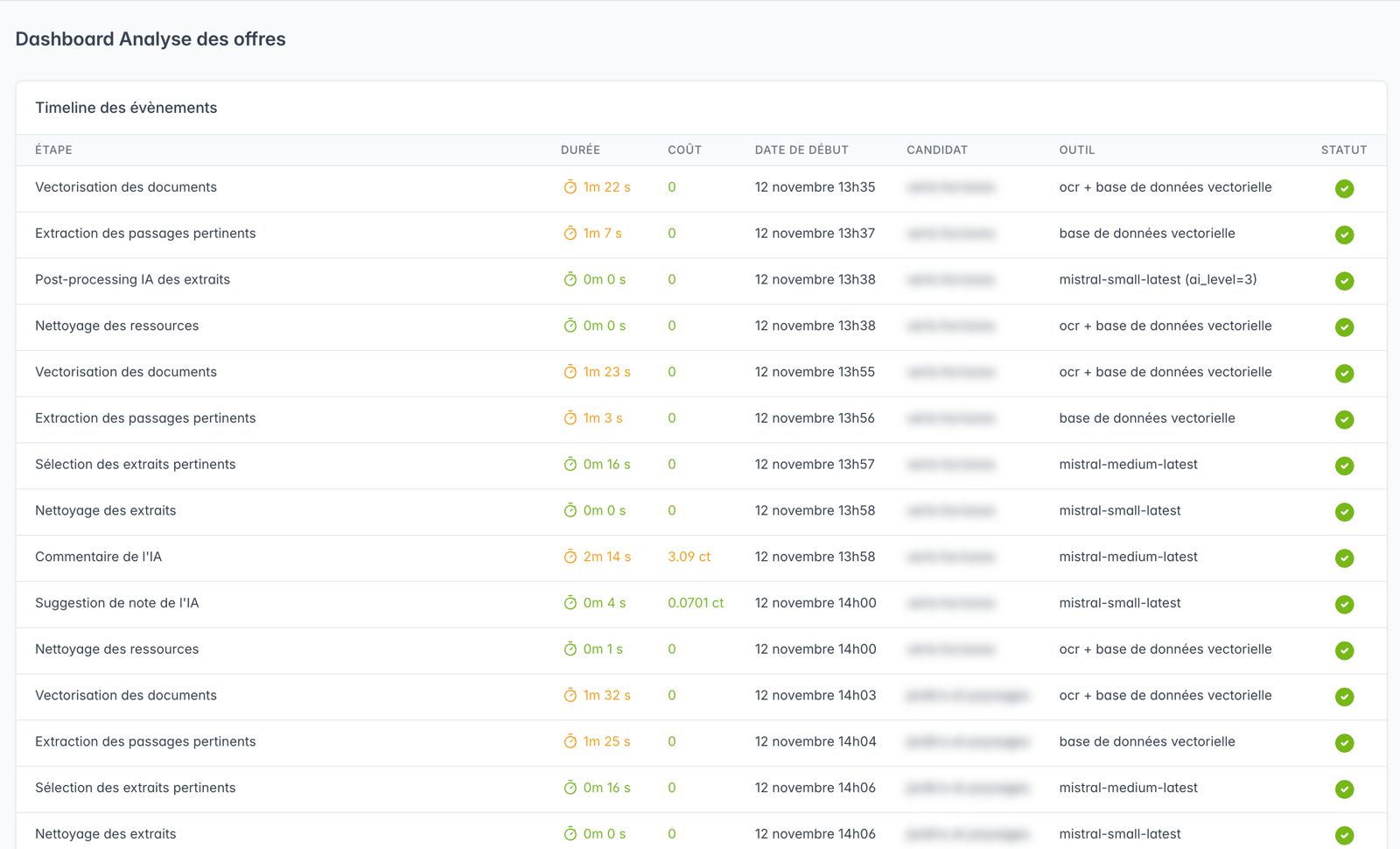
Pour chaque couple (tâche - outil), il faut mesurer temps de réponse, coût marginal, qualité fonctionnelle (le résultat est-il ou non satisfaisant pour l'acheteur qui analyse la proposition commerciale du candidat ?).
La séquences des toutes les tâches IA est spécifiquement suivie, de telle sorte qu'on puisse apprécier la performance globale de la configuration étudiée, et identifier précisément le coût et la durée d'analyse d'un mémoire technique type.
4 - Benchmark continu des meilleurs modèles IA sous contrainte de souveraineté
Un pré-requis général de nos clients publics (ministères, régions, départements, etc.) est la garantie de sécurité et de souveraineté des composants IA utilisés : il est donc nécessaire d'adopter des technologies souveraines (ex : Mistral) ou des modèles open source, éventuellement étrangers, mais hébergés en France chez des fournisseurs de premier plan (par exemple chez OVHCloud ou Scaleway). Actuellement, nous testons régulièrement une vingtaine de LLM, pour identifier la combinaison la plus performante sur une fonctionnalité donnée (Génération de CCTP, Analyse des offres, Détection de fraude aux subventions, etc.)
Ces tests sont permanents du fait des sorties régulières de nouvelles versions open source de modèles éprouvés, ou de nouveaux modèles. Ces travaux sont le plus souvent réalisés en interne, et parfois, dans le cadre de partenariats précis, avec un client désireux de travailler avec Atexo sur ses propres données pour valider ensemble les meilleurs choix techniques. Des bancs de tests sont ainsi mis en place pour comparer, sur un même jeu de données, les résultats produits par différents LLM utilisés.
5 - Traçabilité des sources
La crainte générale des utilisateurs d'IA est la difficulté à obtenir des références exactes, et non uniquement plausibles. Le juriste familier de certaines jurisprudences ou le simple amateur de poèmes classiques constatent simplement avec ChatGPT que la reproduction précise d'un texte exact est encore très incertaine.
Dans le cas de l'analyse des offres, pour chaque critère de notation, il est nécessaire d'appuyer le commentaire argumenté sur des passages précis du Mémoire technique qui fondent ce commentaire. Ainsi, l'acheteur public vérifie la bonne compréhension par l'IA du sujet traité, et affine, le cas échéant, le commentaire final sur lequel il s'engage.
Il est alors nécessaire de ne pas utiliser l'IA pour "recopier" des extraits de Mémoire technique, mais des fonctions usuelles informatiques qui restituent avec exactitude l'extrait de texte voulu. En complément, nous avons choisi de présenter une photo (image) de la partie de Mémoire technique concernée, afin que l'acheteur public soit parfaitement rassuré sur le fait que les sources sont authentiques.
Comme beaucoup de nos confrères éditeurs, nous avons la conviction que l'IA sera dans quelques années une partie centrale des logiciels que nous proposons. Plus que des chantiers techniques isolés, nous nous efforçons de développer nos outils IA avec professionnalisme et transparence, pour rassurer et convaincre nos clients que, sans être déjà parfaitement au point, ces outils vont aider grandement les utilisateurs dans leurs travaux quotidiens.